1
2 #version 310 es
3 precision highp float;
4
5 layout(local_size_x = 16, local_size_y = 16) in;
6 layout(rgba32f, binding = 1) uniform mediump writeonly image2D img_output;
7 layout(location = 2) uniform int iterations;
8
9 void main() {
10 vec2 p = (vec2(gl_GlobalInvocationID.xy) / vec2(256.,256.) - vec2(0.5)) * vec2(3.);
11 int r = 0;
12
13 for(int i = 0; i < iterations / 4; i++) {
14 if(dot(p, p) < 10.) {
15 r++;
16 }
17 p = vec2(p.x*p.x - p.y*p.y + 0.7885, 2.*p.x*p.y);
18 if(dot(p, p) < 10.) {
19 r++;
20 }
21 p = vec2(p.x*p.x - p.y*p.y + 0.7885, 2.*p.x*p.y);
22 if(dot(p, p) < 10.) {
23 r++;
24 }
25 p = vec2(p.x*p.x - p.y*p.y + 0.7885, 2.*p.x*p.y);
26 if(dot(p, p) < 10.) {
27 r++;
28 }
29 p = vec2(p.x*p.x - p.y*p.y + 0.7885, 2.*p.x*p.y);
30 }
31
32 float n = float(r) / float(iterations) * 4.;
33
34 imageStore(img_output, ivec2(gl_GlobalInvocationID.xy),
35 vec4(0.5-cos(n*75.0)/2.0,0.5-cos(n* 120.0)/2.0,0.5-cos(n*165.0)/2.0,1.0));
36 }
37
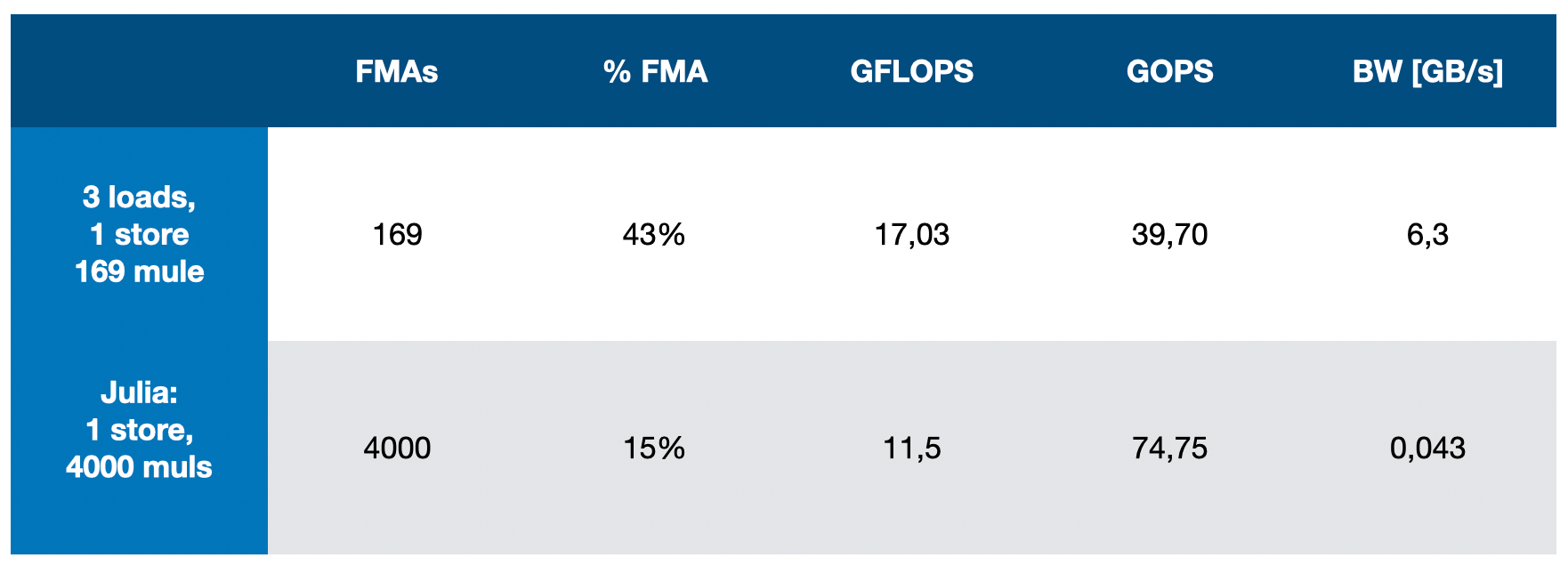
36.76 GFLOPS 70.12 MB/s 14.26 ms
FMAs: 59.15% (42 / 71)
clause_0:
ds(0) nbb r_uncond ncph
{
*NOP t0
+U32_TO_F32 t1, r60
*FMA.f32 r0:t0, t1, 0x3b800000 /* 0.003906 */, 0xbf000000 /* -0.500000 */
+U32_TO_F32 t1, r61
*FMA.f32 r1:t0, t1, 0x3b800000 /* 0.003906 */, 0xbf000000 /* -0.500000 */
+NOP t1
*FMA.f32 r0:t0, r0, 0x40400000 /* 3.000000 */, #0.neg
+NOP t1
*FMA.f32 r1:t0, r1, 0x40400000 /* 3.000000 */, #0.neg
+MOV.i32 r2:t1, 0x00000000 /* 0.000000 */
*NOP t0
+MOV.i32 r3:t1, t1
}
clause_6:
ds(0) nbb r_uncond ncph
{
*NOP t0
+MOV.i32 t1, 0xffffffff /* -nan */
*CSEL.s32.gt t0, u0.w0, t1, u0.w0, t1
+NOP t1
*CSEL.s32.gt r4:t0, 0x00000001 /* 0.000000 */, t0, t0, 0x00000001 /* 0.000000 */
+NOP t1
*NOP t0
+IABS.s32 t1, u0.w0
*RSHIFT_OR.i32 t0, t1, #0, 0x00000002 /* 0.000000 */
+NOP t1
*IMUL.i32 t0, r4, t0
+ICMP.s32.m1.ge t1, r2, t
*NOP t0
+BRANCHZ.i16.eq t1, t1.h0, clause_14
}
clause_12:
ds(0) nbb
{
*NOP t0
+JUMP t1, clause_36
}
clause_14:
ds(0) nbb ncph
{
*NOP t0
+MOV.i32 r4:t1, r1
}
clause_15:
ds(0) nbb ncph
{
*FMA.f32 r4:t0, r1, r4, #0.neg
+MOV.i32 t1, r0
*FMA.f32 r5:t0, r0, t1, t0
+NOP t1
*NOP t0
+IADD.s32 t1, r3, 0x00000001 /* 0.000000 */
*FCMP.f32.lt.m1 t0, r5, 0x41200000 /* 10.000000 */
+MUX.i32 r3:t1, r3, t1, t
*NOP t0
+MOV.i32 t1, r0
*FMA.f32 t0, r0, t1, 0x3f49db23 /* 0.788500 */
+FADD.f32 r4:t1, t, r4.neg
*MOV.i32 t0, r0
+FADD.f32 t1, r0, t
*FMA.f32 r0:t0, t1, r1, #0.neg
+NOP t1
}
clause_22:
ds(0) nbb ncph
{
*FMA.f32 r1:t0, r0, r0, #0.neg
+NOP t1
*FMA.f32 t0, r4, r4, t0
+IADD.s32 t1, r3, 0x00000001 /* 0.000000 */
*FCMP.f32.lt.m1 t0, t0, 0x41200000 /* 10.000000 */
+MUX.i32 r3:t1, r3, t1, t
*FMA.f32 r5:t0, r4, r4, 0x3f49db23 /* 0.788500 */
+FADD.f32 t1, r4, r4
*FMA.f32 r0:t0, t1, r0, #0.neg
+NOP t1
*FMA.f32 r4:t0, t0, t0, #0.neg
+FADD.f32 r1:t1, r5, r1.neg
*FMA.f32 t0, t1, t1, t0
+IADD.s32 t1, r3, 0x00000001 /* 0.000000 */
*FCMP.f32.lt.m1 t0, t0, 0x41200000 /* 10.000000 */
+MUX.i32 r3:t1, r3, t1, t
}
clause_29:
ds(0) nbb r_uncond
{
*FMA.f32 r5:t0, r1, r1, 0x3f49db23 /* 0.788500 */
+FADD.f32 t1, r1, r1
*FMA.f32 r1:t0, t1, r0, #0.neg
+NOP t1
*FMA.f32 r0:t0, t0, t0, #0.neg
+FADD.f32 r4:t1, r5, r4.neg
*FMA.f32 t0, t1, t1, t0
+IADD.s32 t1, r3, 0x00000001 /* 0.000000 */
*FCMP.f32.lt.m1 t0, t0, 0x41200000 /* 10.000000 */
+MUX.i32 r3:t1, r3, t1, t
*FMA.f32 t0, r4, r4, 0x3f49db23 /* 0.788500 */
+FADD.f32 r0:t1, t, r0.neg
*FADD.f32 t0, r4, r4
+IADD.s32 r2:t1, r2, 0x00000001 /* 0.000000 */
*FMA.f32 r1:t0, t0, r1, #0.neg
+JUMP t1, clause_6
}
clause_36:
ds(0) nbb ncph
{
*MOV.i32 t0, r3
+S32_TO_F32 r0:t1, t
*NOP t0
+S32_TO_F32 t1, u0.w0
*NOP t0
+FRCP.f32 t1, t1
*FMA.f32 r0:t0, r0, t1, #0.neg
+NOP t1
}
clause_39:
ds(0) nbb ncph
{
*FMA.f32 r1:t0, 0x43960000 /* 300.000000 */, r0, #0.neg
+NOP t1
*FMA.f32 r2:t0, t0, 0x3f22f98c /* 0.636620 */, 0x49400000 /* 786432.000000 */
+FADD.f32 t1, t, 0x49400000 /* 786432.000000 */.neg
*FMA.f32 r1:t0, t1, 0xbfc90fd0 /* -1.570795 */, r1
+FSIN_TABLE.u6 r3:t1, t0
*FMA_RSCALE.f32 t0, t0, t0, #0.neg, 0xffffffff /* -nan */
+FCOS_TABLE.u6 r2:t1, r2
*FMA.f32 t0, t0, t1.neg, #0.neg
+NOP t1
*FMA.f32.clamp_m1_1 t0, r1, r3.neg, t0
+NOP t1
*NOP t0
+FADD.f32 r1:t1, t0, r2
*FMA.f32 r2:t0, 0x43f00000 /* 480.000000 */, r0, #0.neg
+NOP t1
}
clause_46:
ds(0) nbb ncph next_attr
{
*FMA.f32 r3:t0, r2, 0x3f22f98c /* 0.636620 */, 0x49400000 /* 786432.000000 */
+FADD.f32 t1, t, 0x49400000 /* 786432.000000 */.neg
*FMA.f32 r2:t0, t1, 0xbfc90fd0 /* -1.570795 */, r2
+FSIN_TABLE.u6 r4:t1, t0
*FMA_RSCALE.f32 t0, t0, t0, #0.neg, 0xffffffff /* -nan */
+FCOS_TABLE.u6 r3:t1, r3
*FMA.f32 t0, t0, t1.neg, #0.neg
+NOP t1
*FMA.f32.clamp_m1_1 t0, r2, r4.neg, t0
+NOP t1
*FMA.f32 r0:t0, 0x44250000 /* 660.000000 */, r0, #0.neg
+FADD.f32 r2:t1, t0, r3
*FMA.f32 r3:t0, t0, 0x3f22f98c /* 0.636620 */, 0x49400000 /* 786432.000000 */
+NOP t1
*NOP t0
+FADD.f32 r4:t1, t0, 0x49400000 /* 786432.000000 */.neg
}
clause_53:
ds(0) nbb attr ncph next_store dwb(0)
{
*FMA.f32 r0:t0, r4, 0xbfc90fd0 /* -1.570795 */, r0
+FSIN_TABLE.u6 r4:t1, r3
*FMA_RSCALE.f32 t0, t0, t0, #0.neg, 0xffffffff /* -nan */
+FCOS_TABLE.u6 r3:t1, r3
*FMA.f32 t0, t0, t1.neg, #0.neg
+NOP t1
*FMA.f32.clamp_m1_1 t0, r0, r4.neg, t0
+NOP t1
*NOP t0
+FADD.f32 t1, t0, r3
*FMA.f32 t0, t1, 0x3f000000 /* 0.500000 */, #0.neg
+FADD.f32 t1, 0x3f000000 /* 0.500000 */, t.neg
*MOV.i32 r3:t0, t1
+MKVEC.v2i16 t1, r60, r61
*DTSEL_IMM.attribute_1 t0, t1
+LEA_ATTR_TEX.f32 t1, t, #0.x, #0.x, @r5
}
clause_60:
ds(0) eos store
{
*FMA.f32 t0, r1, 0x3f000000 /* 0.500000 */, #0.neg
+FADD.f32 r1:t1, 0x3f000000 /* 0.500000 */, t.neg
*FMA.f32 t0, r2, 0x3f000000 /* 0.500000 */, #0.neg
+FADD.f32 r2:t1, 0x3f000000 /* 0.500000 */, t.neg
*NOP t0
+MOV.i32 r4:t1, 0x3f800000 /* 1.000000 */
*NOP t0
+ST_CVT.v4 t1, r5, r6, r7, @r1
}
shader14548 - MESA_SHADER_COMPUTE shader: 0 inst, 0 bundles, 0 quadwords, 0 registers, 4 threads, 0 loops, 0:0 spills:fills
_files/figure-html/cell-3-output-1.png)
_files/figure-html/cell-4-output-2.png)
_files/figure-html/cell-6-output-1.png)